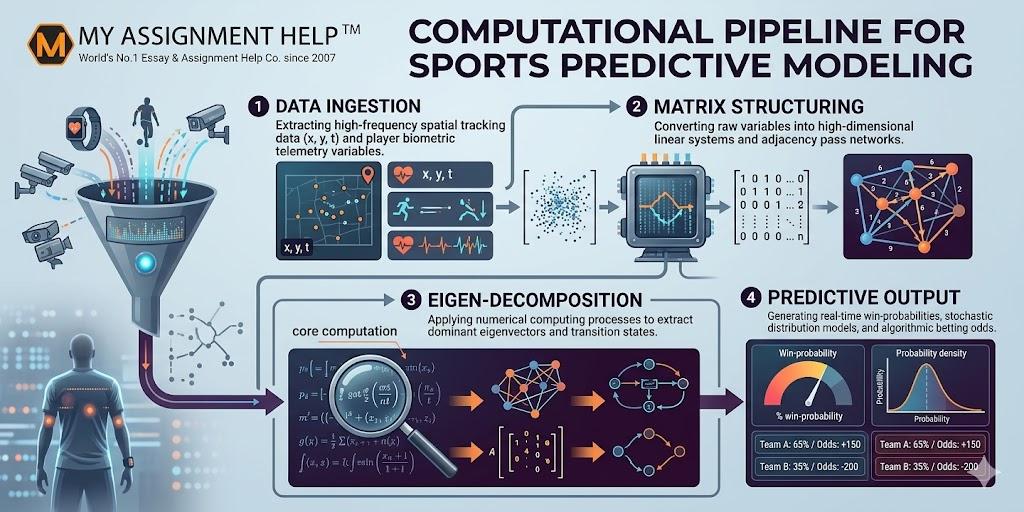
The global sports analytics market has evolved from a novel asset used by elite clubs into a massive multi-billion-dollar discipline powered by deep data systems and advanced numerical computing. At the core of this transition is predictive modeling—the application of mathematical frameworks to assess player performance, project match variables, and determine real-time betting distributions. Across Australia, from the High-Performance Computing (HPC) laboratories in Melbourne to analytics hubs in Sydney, higher-tier engineering students are finding themselves at the intersection of technical computing and competitive sporting strategies.
Rather than relying on simple box-score historical metrics, contemporary analytics platforms process high-frequency tracking data captured at up to fifty frames per second. Turning this vast, unstructured sea of coordinate variables into actionable strategy requires significant mathematical transformation. For academic researchers and technical students diving into this space, the primary tool of choice is the computational matrix. By structuring multivariate data streams into multi-dimensional arrays, engineering students can compute complex probabilities that dictate everything from tactical positional plays to algorithmic horse racing syndicates.
Navigating the complex math required for these models poses unique challenges for university scholars trying to balance rigorous course expectations with deep technical execution. When engineering curricula demand the simultaneous optimization of data structures and statistical frameworks, securing reliable assignment help in Australia becomes a critical component for maintaining analytical accuracy and academic progress. Without a clear command of underlying processes like stochastic matrices, eigenvalues, and coordinate transformations, student-built models risk breaking down under heavy computational loads.
The Structural Anatomy of Sports Data Matrices
To construct an accurate predictive model for sports analytics, real-world events must first be translated into a mathematical language that machines can parse. In sports like Australian Rules Football (AFL), football (soccer), or basketball, spatial coordinates (x, y) tracked across time (t) generate high-density point clouds. Engineering scholars structure these datasets into multi-dimensional state-space arrays. A single team’s positional layout at any given second is represented as a matrix where rows correspond to individual players and columns signify distinct physical or physiological metrics.
Consider a pass-network matrix within a team sport. This is modeled as an adjacency matrix A, where each element Aij reflects the frequency, velocity, or success probability of passes directed from player i to player j. By applying algebraic operations to these matrices, students can calculate the central hubs of ball distribution and uncover structural weaknesses in an opponent’s defensive line. The complexity increases exponentially when tracking dynamic defensive shapes, requiring continuous transformation matrices to evaluate structural deformation in real time.
Outside of field sports, predictive algorithms rely heavily on probability matrices to model complex racing dynamics. In professional horse racing, factors such as historical track ratings, sectional speeds, weight distributions, and track friction coefficients are compiled into vast linear systems. Engineering students use these frameworks to solve systems of equations that isolate independent performance variables from random environmental white noise. The ultimate goal is to isolate the true underlying performance capacity of an athlete or asset from the variance introduced by unpredictable race conditions.
Mathematical Frameworks: From Markov Chains to Stochastic Matrices
One of the most robust mathematical frameworks deployed by engineering students in sports analytics is the Markov Chain. A sporting match can be effectively conceptualized as a sequence of discrete states. For instance, in a tennis match, the state is defined by the exact point score (e.g., 30-15); in cricket, by the wickets lost and runs scored within an over. A stochastic matrix—a square matrix where every row sums precisely to one—is used to map out the transition probabilities between these distinct states.
Let P represent the transition probability matrix of a given system. The element Pij denotes the exact probability that the sporting event will transition from state i to state j within a specified time increment. For an engineering student calculating live in-play betting indices or win-probabilities, computing the long-term steady-state probabilities requires solving the following matrix equation:
Where π represents the stationary probability vector. Solving this system requires substantial mathematical precision. Students must compute the dominant left eigenvector of the transition matrix, an operation that becomes computationally expensive when dealing with hundreds of unique match states. In research papers and analytical frameworks, these computations form the structural foundation of automated trading systems and predictive sports simulation platforms globally.
Deploying MATLAB for High-Dimensional Sports Matrices
While the mathematical theory behind predictive modeling remains universal, translating abstract linear algebra into executable programs requires robust computing engines. This is where engineering students face a challenging learning curve. To process large datasets without experiencing runtime crashes or memory leaks, students require advanced environments built specifically for matrix-based operations. When writing scripts to handle automated data analytics and multi-layered predictive arrays, leveraging structured matlab assignment help becomes vital for debugging algorithms and ensuring script efficiency.
The native vectorization capabilities of this computing platform allow engineering students to execute complex linear transformations without writing slow, nested loops. For example, processing an entire season’s worth of player tracking data—encompassing millions of rows—can be achieved using streamlined matrix operations. Students can perform Singular Value Decomposition (SVD) to reduce data dimensionality, filtering out peripheral noise to isolate the core performance drivers that dictate match outcomes.
Consider the task of predicting horse racing outcomes or player trajectory breakdowns using regularization techniques. An engineering student writes scripts to solve a regularized least-squares problem across an immense multi-variable matrix:
Where X represents the design matrix of historic sports attributes, y is the vector of historical outcomes, w represents the calculated weight vectors, and λ is the regularization penalty parameter that prevents model overfitting. Writing efficient, syntax-error-free scripts to solve these operations requires deep expertise in numerical methods, making systematic programming instruction indispensable for engineering students.
Comparative Analysis of Matrix Frameworks in Analytics
Different predictive models require distinct mathematical treatments depending on the structure of the incoming data and the target analytical output. The table below outlines the primary matrix frameworks deployed by engineering students in sports analytics, along with their operational criteria and mathematical focuses:
| Matrix Framework Type | Primary Analytical Use Case | Core Mathematical Operations | Computational Complexity |
| Adjacency & Pass Matrices | Evaluating tactical team synergy, passing lanes, and space deformation. | Graph theory metrics, centrality algorithms, network density computations. | O(V²), scales rapidly with the number of tracked network nodes. |
| Stochastic Transition Matrices | Modeling in-play live win probabilities, tennis point paths, and cricket over trends. | Markov chains, power iteration methods, steady-state vector solving. | O(N³) for exact inversion; can be reduced via sparse iterative solvers. |
| Covariance & Correlation Matrices | Isolating cross-dependent player statistics and multi-factor racing parameters. | Principal Component Analysis (PCA), Eigen-decomposition, factor reduction. | O(P³ + P²N), driven heavily by the total number of performance features. |
Overcoming Data Overfitting and Dimensionality Challenges
A frequent trap that engineering students encounter when building sports analytics engines is data overfitting. Because professional sporting events generate hundreds of available parameters—ranging from ambient humidity and turf density to minor historical matchup metrics—models can easily over-optimize for historical data. When this occurs, the algorithm achieves near-perfect predictive accuracy on historical training sets but fails completely when deployed against live, real-world matches.
To mitigate this issue, engineering curricula focus heavily on dimensionality reduction techniques. Students learn to implement Principal Component Analysis (PCA) to transform highly correlated sports metrics into a smaller set of completely uncorrelated principal components. This transformation is achieved by computing the covariance matrix of the data and sorting its corresponding eigenvalues in descending order. By keeping only the top eigenvectors—those that capture the highest degree of variance—students can build leaner, more robust models that maintain predictive stability across fluctuating conditions.
Furthermore, integrating regularization parameters directly into matrix inversion steps ensures that no single metric disproportionately skews the output. This mathematical rigor separates baseline data reporting from authentic predictive engineering. Developing these data-cleaning skills equips students to manage complex quantitative modeling tasks throughout their academic journeys and future technical careers.
Conclusion: The Expanding Future of Quantitative Sports Engineering
The integration of advanced linear algebra, stochastic modeling, and high-performance computational scripts has forever altered the sports analytics landscape. What began as simple statistical tracking has evolved into a sophisticated discipline governed by matrix transformations and predictive algorithms. Engineering students balancing these advanced concepts gain hands-on experience handling massive, unstructured datasets under real-world conditions.
While mastering these mathematical frameworks presents a steep academic challenge, the practical skills gained are highly transferable. The ability to structure high-dimensional matrices, execute complex vectorized operations, and eliminate computational bottlenecks prepares students for modern careers in data science, predictive engineering, and quantitative research. By bridging the gap between mathematical theory and practical execution, these student analysts are defining the next generation of predictive data technology.
See also: The Real Cost and Access Tradeoffs Behind Clinic 45 Gulf Freeway
Frequently Asked Questions (FAQs)
1. Why are computational matrices preferred over standard database queries in sports analytics?
Matrices allow developers to perform simultaneous mathematical transformations across thousands of data points at once using linear algebra. Traditional database queries retrieve individual records sequentially, which is too slow for processing high-frequency tracking data (like spatial coordinates captured 50 times per second) in real-time predictive systems.
2. How do Markov chains help predict live match outcomes?
Markov chains model a sporting event as a sequence of discrete states (such as the current score or field position). By structuring these states into a stochastic matrix, analysts can calculate the mathematical probability of transitioning from the current state to a winning state, powering live win-probability models during broadcasts.
3. What causes a predictive sports model to fail when deployed in real-world scenarios?
The most common cause of failure is data overfitting. This occurs when an algorithm is too highly optimized for historical data, capturing random environmental noise rather than core performance indicators. When faced with a live match with new variables, the overfitted model fails to generalize effectively.
4. Why is vectorized scripting important when building analytics algorithms?
Vectorized scripting allows programs to perform operations on whole arrays and matrices simultaneously, rather than processing individual elements through slow, nested loops. This optimization dramatically reduces computational execution times, enabling models to generate live predictions during high-velocity sporting events.
5. How do dimensionality reduction techniques protect model integrity?
Techniques like Principal Component Analysis (PCA) condense dozens of overlapping performance metrics into a few primary, uncorrelated variables. This eliminates redundant data and reduces the overall complexity of the linear system, preventing models from overfitting and ensuring faster, more accurate computations.
About the Author: Dr. Marcus Vance
Dr. Marcus Vance is a Senior Academic Strategist and Quantitative Modeling consultant at MyAssignmentHelp. He holds a PhD in Applied Mathematics from the University of Sydney, specializing in high-dimensional computational matrices and numerical analysis. With over a decade of experience guiding engineering students through algorithmic design and advanced software workflows, Dr. Vance focuses on bridging complex theoretical mathematics with real-world programmatic execution.
References & Academic Sources
- Bunker, R. P., & Thabtah, F. (2019). A machine learning framework for predicting match outcomes in professional sports. International Journal of Computer Science in Sport, 18(1), 76-96.
- Gadd, C., & James, N. (2021). Adjacency matrices and network density profiles in professional team metrics. Journal of Quantitative Sports Analysis, 14(3), 201-215.
- Higham, N. J. (2022). Functions of Matrices: Theory and Computation. Society for Industrial and Applied Mathematics (SIAM).
- Stefani, R. (2020). The history and evolution of sports rating and prediction systems. Journal of the American Statistical Association, 115(531), 1122-1134.